[Essay] 인공지능 무엇이 달라지고 있는가?
이 글은 인공신경망(ANN)이란 무엇인지 간략히 알아보고 앞으로의 변화에 대해 주관적인 생각을 담아 작성하였습니다. 맞춤법이나 틀린 내용이 있다면 아래의 댓글을 통해 알려주시면 감사하겠습니다.
인공지능 무엇이 달라지고 있는가?
1996년 IBM에서 발표한 딥 블루라는 컴퓨터가 세상에 발표되었다. 인간과의 체스 대결에서 4 대 2로 패배했지만 1년 뒤, 정식 체스 토너먼트에서 세계 챔피언을 3.5대 2.5로 이겼다. 대중들은 큰 충격을 받았지만, 인공지능이라는 말보다는 하드웨어의 발전이라는 단어가 더 어울렸다. 그 후, 2015년 Google DeepMind에서 AI 바둑 프로그램 알파고를 발표했다. 인간과 알파고의 바둑대결에서 인간은 단 한 경기 밖에 승리하지 못했다.
현재 인공지능은 단순한 SF소설이 아닌 현실이 되고 있다. 우리는 자율주행 자동차, 인터넷 쇼핑몰, 스마트 비서 등 일상생활에서 약 인공지능을 접하고 있다. 인류는 강 인공지능을 만들 수 있을까? SF영화처럼 인간과 인공지능은 친구가 될 수 있을까? 아니면 인공지능이 인간을 뛰어넘는 상황이 올 수 있을까? 나는 이 질의의 해답을 구하기 위해 Artificial Neural Network(인공 신경망)에 대해 알아보려 한다. 인공 신경망은 생물학의 신경망에서 영감을 얻은 통계학적 학습 알고리즘이다. 지금부터 강 인공지능이 실현 가능한 기술인지와 인공지능에 대한 나의 생각을 풀어나가겠다.
Aritificial Neural Network(인공신경망)
먼저, 위키백과에서는 인공신경망을 기계학습과 신경망에서 영감을 얻은 통계학적 학습 알고리즘이라 정의하고 있다. 인공신경망은 상호 연결하는 노드들로 구성이 되어있는데 각 노드들은 학습을 통해 시냅스로 결합이 되고 이는 거대한 정보의 네트워크를 형성하게 되는데 나는 이 기술을 인공지능의 뇌를 만드는 과정이라 생각한다. 뇌를 만든다는 것은 하나의 생명을 만드는 일과 동일하다. 과연, 우리는 인공생명을 만들 수 있을까? 인공신경망은 어떤 원리로 형성되고 어떤 잠재력을 가지고 있을까? 문제점은 없을까? 이 의문들을 중점으로 인공신경망에 대해 알아보았다.
ANN(인공신경망)의 역사
인공지능을 구현하는 방법은 크게 2종류로 나눌 수 있다. 첫째, 목표로 하는 인간의 두뇌 등 생물학적 두뇌작용을 모방함으로써 스스로 지능을 축적해 가는 신경망 기법. 두 번째, 지능을 법칙으로 표현하여 논리구조로 프로그램하는 AI 기법. 그 중에서도 첫 번째 기법인 인공 신경망은 1943년 Warren McCulloch와 Walter Pitts의 논문인 <A logical calculus of ideas immanent in nervous activity>로부터 시작되었다. 각 신경세포(neuron)의 기능은 매우 단순하나, 이들이 상호 연결됨으로써 복잡한 계산을 수행하는 신경 시스템의 기초를 마련한 이 논문은, 현대 컴퓨터의 기반을 이루는 모든 Boolean 논리 표현은 2진 출력을 갖는 신경세포로 구현 가능함을 보여주었다.
이후, 수많은 학자들은 우리의 두뇌 작용이 각각의 신경세포의 기능에 의한 것이 아니라, 이들이 상호간에 어떻게 연결되어 있는 것인가에 대해 고민하게 된다. 그 중 Donald Hebb이라는 심리학자가 세운 가설은 신경 시스템은 기존의 synapse를 이용하여 synapse를 스스로 재구성한다는 것이다. 즉, 신경세포 A가 계속해서 신경세포 B의 활성화에 기여한다면 A와 B사이의 synapse가 증가한다는 것이다. 이 가설은 ‘헵의 학습법칙’으로 불리며, 신경망 연구에 많은 영향을 끼쳤고 현재까지도 신경망 모델 학습의 직간접적인 영향을 미치고 있다. 이외에도 패턴의 특징을 추출하여 프로그램화 없이 단순한 입력 패턴들을 분류하는 Widrow-Hoff 모델, 단순 계산 기능을 갖는 입력 층과 출력 층으로 구성된 perceptron모델 등 다양한 연구가 이루어졌다.
하지만, 1969년 perceptron 모델이 선형 분리 기능밖에 없고 많은 실제 문제를 해결하지 못한다는 반례가 등장하면서 신경망에도 암흑기가 찾아오게 된다. 그럼에도 불구하고, 많은 학자들이 반례를 다시 반증하기 위한 모델을 연구했고 1982년 John Hopfield의 논문 <Neural networks and physical systems with emergent computational ablilities>은 이론에 치우쳐 왔던 신경망 연구를 공학적 관점에서 접근하는 계기를 마련했다. 그 후, 신경망은 이론뿐만 아니라 광, VLSI를 이용한 하드웨어 구현, 음성인식, 문자인식, 최적화 등 응용문제의 연구가 활발히 시작되었다.
이후, EU의 정보분야 과제인 ESPRIT에서는 25% 이상이 신경망 분야의 과제였으며, 일본은 신경망이 주를 이루는 신정보처리기술을 추진하였다. 이러한 열풍으로 1987년에 형성된 국제신경망학회(International Neural Network Society)는 1년 만에 30여 개국과 2,000여 명의 회원을 확보했고, 지금도 그 수는 계속 증가하고 있다. 상업적 측면에서 대표적으로 Intel, Phillips, 도시바 등 세계적인 반도체 회사들이 이를 이용한 시스템을 발표하고 있다.
신경망이 급 발전한 이유
신경망이 부활하고 급성장한 이유는 무엇일까? 많은 사람들이 오차역전파에 의한 다층구조 perceptron의 발견을 첫째 이유로 들고 있다. 또한, 하드웨어의 빠른 발전이 대규모 시뮬레이션을 빠른 시간 내에 해줄 수 있게 되었다. 그 사이 신경생리학이 발달하여 신경망과 관련한 더 많은 지식들을 얻을 수 있었고, 광학기술의 발달로 병렬 특성이 구현 가능해졌다. 마지막 이유로는 기존의 AI가 한계에 부딪쳤다는 데서 찾을 수 있다. 전문가 시스템의 경우 단순문제에서 성공을 거두었으나, 복잡한 시스템의 경우 자신의 판단에 필요한 법칙을 알지 못했다. 또한 미리 정의된 법칙을 이용하는 AI는 특수 목적을 달성할 수 있을지는 몰라도, 변화되는 상황에 대한 적응 능력이 없고, 병렬처리가 어려웠다. 이와 같은 부분이 AI에서 신경망으로 넘어가는 계기가 되었다.
ANN(인공신경망) 모델링
생물학적 신경망을 모방하여 인공신경망을 모델링한 내용을 살펴보면, 생물적인 뉴런은 node로, 연결 측의 시냅스는 가중치로 모델링 된다. 또한, 수상 돌기를 통해 전기신호가 들어오는 것을 Input으로 다른 뉴런에 전달되는 축삭(Axon)을 Output으로 본다.
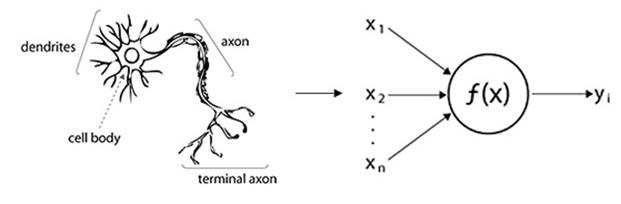
위의 그림은 뉴런을 모형화 한 것이다. 신경세포(뉴런)의 Input은 다수이지만 Output은 하나의 값을 갖는다. f(x)라는 함수에서 여러 Input의 합산이 출력되고, 합산된 값이 설정 값 이상이면 Output이 생기고 이하이면 신호를 보내지 않는다.
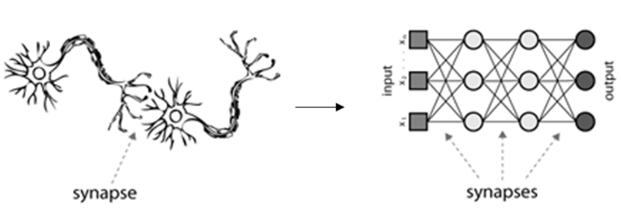
위의 그림은 각 노드간의 연결을 보여준다. 인간의 뉴런이 하나가 아닌 다수가 연결되어 의미 있는 작업을 하듯, 인공신경망의 경우도 개별 노드들의 링크를 통해 서로 연결되며, 복수 개의 계층구조를 가지게 된다. 각 층간의 연결 강도는 가중치를 통해 수정이 가능하며, 계층 구조와 연결강도로 학습과 인지를 위한 분야에 활용 된다.
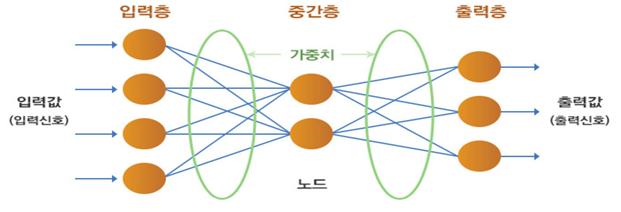
인간의 뇌를 모델링으로 한 인공신경망의 주요 특징은 인간 뇌의 적응성을 활용하여 적응 학습 능력과 병렬구조를 구현하고자 한 것이다. 위의 그림을 보면 각 노드들은 가중치가 있는 링크로 연결되어 있으며, 전체 모델은 가중치를 반복적으로 조정하면서 학습한다. 즉, 가중치는 장기 기억을 위한 노드들의 중요도를 표현하고, 가중치를 반복적으로 조정함으로써 전체 모델을 훈련시키는 것이다. 이러한 반복들은 경험의 일반화로 인공지능이 형성되는 과정이다. 중간층이 2개 이상일 경우, 심층신경망이라 하는데, 이를 통해 이루어지는 학습을 딥러닝이라 한다.
ANN(인공신경망)의 한계와 극복
지능을 끊임없이 만들어 나가지만 그에 대한 문제도 존재한다. 단순한 문제의 경우 소수의 노드를 통해서 학습 가능하지만, 문제가 복잡해질수록 다수의 노드가 필요하고 그에 따라 계층구조가 깊어진다. 첫 번째는 계층구조가 깊어짐에 따라 학습에 소요되는 시간이 너무 오래 걸리게 된다. 두 번째는 부분 최적화로 인해 다른 문제를 만날 경우 해결하기 어렵다는 점이다. 세 번째는 사전 훈련 데이터에 지나치게 의존도가 크므로 제대로 작동이 안 되는 문제가 발생할 수 있다는 점이다.
하지만, 시간의 흐름에 따라 한계도 조금씩 사라지고 있다. 먼저, 알고리즘의 개선이다. 각 계층마다 개별 학습을 하거나, 문제 해결에 필요 없는 노드의 링크는 잠시 중지함으로써 학습 소요 시간을 줄일 수 있다. 또한, 빅데이터의 출현은 의존도의 문제와 최적화의 문제를 해결해 주고 있다. 검증된 대량의 데이터를 테스트 셋으로 이용함으로써 정확도는 더 증가하는 중이다. 하드웨어의 발전도 빠질 수 없다. GPU의 성능이 상향됨에 따라 복잡한 매트릭스와 벡터 계산이 혼재해 있는 경우 몇 주의 시간이 소요되는 작업을 몇 시간으로 줄어들게 된다.
위와 같이 기존의 한계점이 극복됨으로써, 인공신경망은 단순한 함수 예측을 넘어서 음성인식, 얼굴인식, 물체인식, 문자인식 등 다양한 분야에서 사용되고 있다. 2년 전, 우리는 딥러닝과 인공신경망을 이용하여 ‘알파고’라는 컴퓨터를 세상에 내놓았다. ‘알파고’가 은퇴한 지금 구글 딥마인드는 다음 도전 상대로 ‘스타크래프트’를 지목했다. 인공지능의 도전은 내년 중 성사될 가능성이 높다고 얘기하고 있다. 인간의 편에서 다른 한 쪽은 소프트웨어의 편에서 새롭게 이루어질 경기의 결과를 기대한다.
ANN(인공신경망)과 인공지능에 대한 생각
인공신경망은 인간의 뇌를 모델화 한다는 점에서 인공지능의 중심이 되는 기술로도 볼 수 있다. 이 기술이 실용화 및 안정화된다면, 강 인공지능의 시대가 왔다고 말할 수 있을 것이다. 인공지능을 연구하는 사람들에게는 긍정적인 부분임과 동시에 인공지능을 반대하는 사람들에게는 끊임없는 논란의 소지가 된다. 테슬라의 CEO 엘론 머스크는 “인공지능 연구는 우리가 악마를 소환하는 것과 마찬가지이고 핵무기보다 위험하다.” 라고 말했고, 물리학자 스티븐 호킹은 “인류의 발전은 생물학적 진화 속도로 인해 제한되기 때문에 인공지능 발전 속도와 경쟁할 수 없다.”고 말했다. 현재까지의 인공지능 기술은 수긍할 수 있지만, 강 인공지능의 시대가 오는 것은 인류의 멸종으로 연결될 수 있다는 것이다. 나 또한 인공지능에 대해 긍정적인 생각은 아니다. 다음은 내가 인공지능에 대해 부정적인 생각을 가지는 이유이다.
먼저, 완벽한 인공신경망을 통해 강 인공지능이 실세계에 등장했을 때, 문제가 발생하지 않을 것이라고 100% 확신 할 수 있는가? 불가능하다. 아무리 완벽한 신경망이라도 외부의 충격이나 경험, 바이러스에 대한 문제로부터 보호될 수 없다. 인공지능은 사람을 모델화하여 만들어진 것이고 사람은 완벽하지 않다. 인공지능 로봇 내부 센서 한 부분이 외부 충격에 의해 망가져, 신경망 중 노드의 0.1%가 불능이 되었다고 가정하자. 이 0.1%의 눈에 띄지 않을 수도 있다. 하지만 0.1%의 오류로 학습이 중첩되다보면, 예상과 다른 학습결과를 내놓게 될 것이고 그 결과가 우리에게 어떤 영향을 미칠지는 아무도 모른다.
두 번째로는 인간이 만들었다는 점이다. 인간은 완벽한 동물이 아니다. 법이 정해져 있음에도 법을 어기고 법 또한 절대적인 규칙이라고 바라볼 수 없다. 우리는 링크에 가중치를 주어 학습결과를 유도한다. 지금까지는 간단한 학습이기에 도덕적 규범이나 법의 문제에 위반이 되지 않았지만, 강 인공지능을 만들기 위해서는 더 많고 어려운 학습이 필요하다. 그렇다면 법이나 도덕성에 관련된 학습의 기준은 어떻게 세울 것인가? 인간은 개개인마다 각자의 가치관을 가지고 법을 지키면서 살아간다. 가치관은 환경에 따라 달라지고, 같은 가치관을 가지고 있는 사람은 세상에 존재하지 않는다. 그런 가치관의 기준을 정의하는 것은 불가능한 것이 아닐까? 만일 정의하더라도, 인공지능은 동일한 데이터로 학습되므로 비슷한 가치관을 가지고 태어날 것이다. 인간의 갈등은 가치관의 차이로부터 발생했고, 우리는 인공지능과의 갈등을 피할 수 없을 것이다.
인공지능의 능력 또한 무시할 수 없다. 인간의 명령이 없다면 컴퓨터는 고철에 불가하다. 하지만 인간 역시 컴퓨터가 없다면 평범한 동물에 불과하다. 인공신경망은 단순한 뇌가 아니다. 인간은 전체 뇌의 10% 밖에 사용하지 않는다고 알려져 있다. 인공신경망이 자신의 신경망을 1%만 사용할 수 있다고 가정해보자. 사람은 보통 동일한 부분의 10%를 사용하지만 인공신경망은 자신이 가지고 있는 데이터를 모두 활용할 수 있다. 즉, 1%라는 데이터만 보여줬을 뿐 숨겨진 데이터와 그에 대한 학습능력은 이미 인간을 뛰어넘은 것이다. 인간은 인공지능을 통제할 수 있다고 생각하지만 인공지능의 개발이 시작된 지금 이미, 인공지능이 인간을 이용하고 있는 것은 아닐까?
물론 인공지능의 활용성과 가능성은 상상을 현실로 만들 수 있다. AI가 적용된 음성비서는 시각장애인의 불편함을 줄여주고 있고, 소프트 뱅크의 ‘Pepper’는 인간의 감정을 인식하고 1인 가구의 친구 역할을 해주고 있다. 인공지능이 사람을 편리하게 해주는 것은 사실이다. 우리는 이미 실생활에서 알게 모르게 인공지능을 사용하고 있고, 그 영향으로 더 많은 것들을 할 수 있게 되었다. 인공지능 개발에 완전히 반대하는 것이 아니다. 단지, 앞에서 말한 문제들을 어떻게 해결하지를 연구하는 것이 우선이 아닐까? 우리는 이 문제를 어떻게 해결해야 할까? 정답은 모른다. 하지만 해답은 인간에게 있을 것이다.
우리는 수많은 SF영화에서 인공지능의 가능성과 문제점들을 인지하고 있다. 영화는 단순한 상상이 아니다. 현실에서 충분히 발생할 수 있다고 공감하기에 많은 사람들이 영화를 보는 것이다. 인공지능에 대한 논쟁은 끊임없이 이어지고 있고 우리는 그 안에서 해답을 찾아야 한다. 서로 다른 입장에서의 대화를 통해 생각하지 못했던 가능성이나 문제점들을 끊임없이 인식해야 하고, 그 속에서 또 다른 가능성과 문제점을 찾아야 한다.
인류는 말도 안 되는 시간동안 빠르게 발전해왔고 앞으로도 발전할 것이다. 단, 우리에게는 아직 시간이 많다. 또한 아직 해결하지 못한 문제들도 많다. 앞으로 나아가는 것도 중요하지만 문제의 해결 또한 중요하지 않을까? 우리는 잠시 쉬어가야 할 필요가 있다.
출처
https://ko.wikipedia.org/wiki
http://www.aistudy.com/neural/nn_model.html
http://blog.daum.net/goodcyk/17490861
http://platum.kr/archives/61177
http://creativeprm.tistory.com/82
https://deeplearning4j.org/kr/neuralnet-overview
http://www.hankookilbo.com/v/87d392339a314e679c2e2d651ce91c99
http://blog.daum.net/kidari1004/16761191
https://ko.wikipedia.org/wiki/
생각보다 긴 글이였지만, 지금까지 읽어주셔서 감사합니다.
